Lançamento do Google Gemini 3.1 Pro


O Google lançou o Gemini 3.1 Pro. O movimento tenta retomar a liderança técnica que o Gemini 3 Pro manteve por poucas semanas no final do ano passado, antes de ser superado pela OpenAI e pela Anthropic. A corrida é essa. Um modelo lidera o leaderboard por um tempo, e logo é superado. A questão que importa para quem toma decisões de tecnologia não é quem está na frente hoje.
O que de fato muda no dia a dia de quem opera com esses modelos.
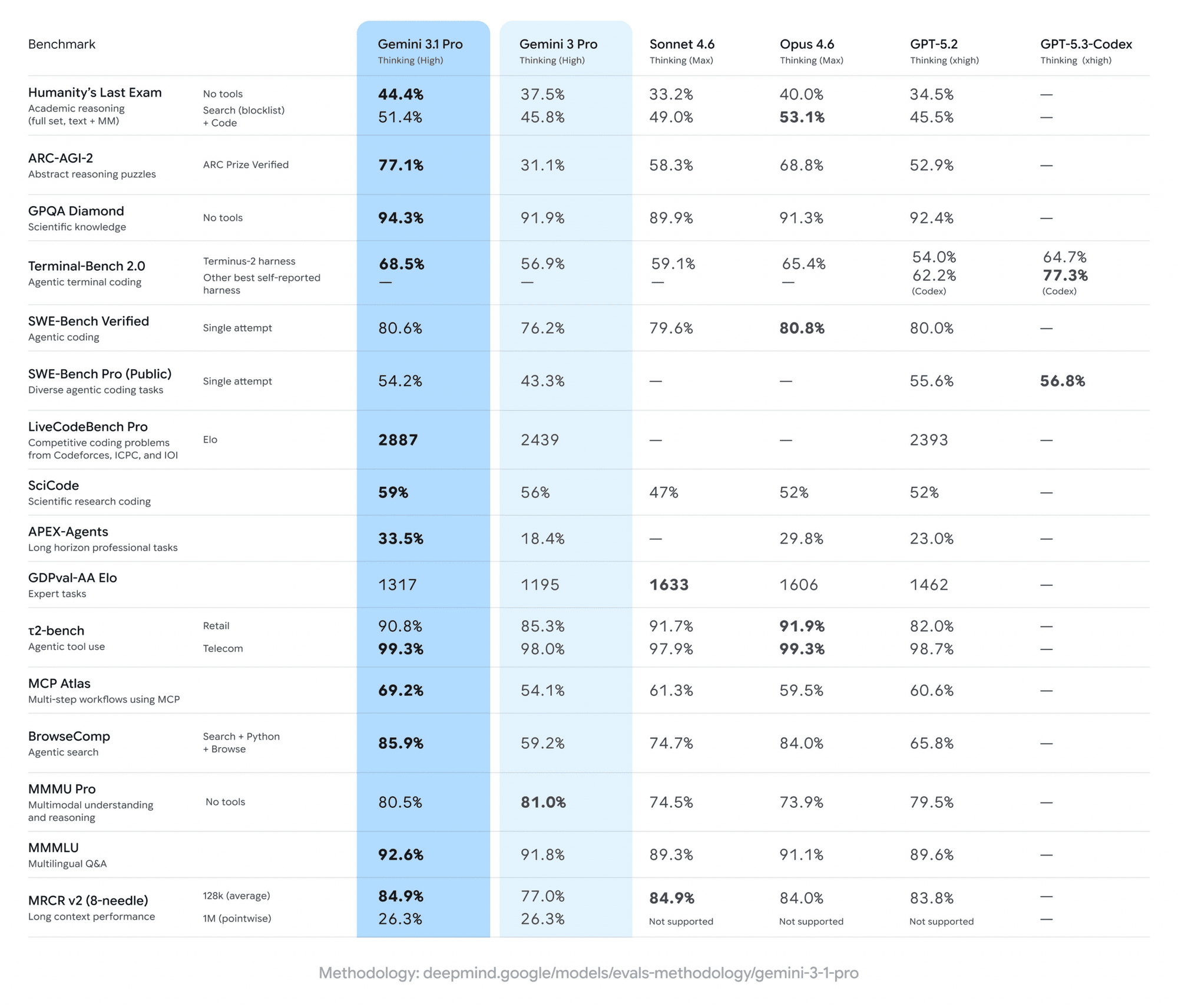
O ponto central do 3.1 Pro é a capacidade de raciocínio. O Google reporta um salto de 31.1% para 77.1% no ARC-AGI-2, um benchmark que avalia a solução de problemas lógicos inéditos. Dobrar a performance em um teste de lógica pura é um feito de engenharia. Mas quem já operou modelos em produção sabe que benchmarks são um campo de provas controlado. Tecnologias promissoras falham com frequência quando confrontadas com a complexidade e a escala do mundo real. A medida de um modelo não está em um paper, mas na sua capacidade de resolver um problema de negócio de forma eficiente e com custo previsível.
O Google parece saber disso ao mirar em aplicações de ciência e engenharia. É um reconhecimento implícito de que a fronteira da IA não está mais nos chatbots de uso geral, mas em ferramentas especializadas que demandam planejamento de múltiplos passos. A capacidade de gerar SVGs animados ou de sintetizar um dashboard da ISS a partir de um stream de telemetria são demonstrações mais relevantes do que qualquer score em um leaderboard.
No entanto, a competição não dá trégua. O Claude Opus 4.6 e o GPT-5.2 ainda mostram vantagens em áreas como a interação com ferramentas externas (tool use). No Arena, um leaderboard baseado em preferência de usuários, o Opus 4.6 ainda leva uma pequena vantagem em texto e código. No Humanity's Last Exam com suporte de ferramentas, o Opus 4.6 também se destaca. Essa é uma deficiência que o Google precisa endereçar. Um modelo que raciocina bem, mas não consegue operar de forma autônoma e confiável em um ecossistema de APIs, tem seu valor prático limitado. A automação que importa é aquela que se integra ao workflow existente sem adicionar complexidade.
Os números em outros benchmarks são fortes. Em conhecimento científico (GPQA Diamond), o 3.1 Pro atinge 94.3%. Em multimodalidade (MMMLU), 92.6%. Em programação (SWE-Bench Verified), fica lado a lado com o Opus 4.6 da Anthropic, com 80.6% contra 80.8%. Em LiveCodeBench Pro, o Elo de 2887 supera tanto o Gemini 3 Pro (2439) quanto o GPT-5.2 (2393). São números que colocam o modelo na conversa, sem dúvida. Mas a percepção de qualidade do usuário final nem sempre é capturada por benchmarks sintéticos.
Manter o preço do Gemini 3 Pro foi uma decisão pragmática. O custo de entrada permanece em US$ 2,00 por milhão de tokens e o de saída em US$ 12,00 por milhão de tokens, para prompts de até 200k. Oferecer mais capacidade de raciocínio pelo mesmo custo é uma forma de baratear a experimentação para os desenvolvedores e, ao mesmo tempo, acelerar a coleta de dados sobre o comportamento do modelo em cenários complexos. É uma troca: o Google oferece performance, e o mercado oferece os casos de uso que irão, de fato, validar a tecnologia. Para quem já opera com a API do Gemini, é um upgrade sem atrito. Para quem está avaliando, o custo por token, especialmente para saídas, ainda é um fator a ser modelado com cuidado em qualquer aplicação de larga escala.
O modelo está disponível em preview no Vertex AI, Google AI Studio, Gemini CLI, Google Antigravity e Android Studio. Para consumidores, chega ao app Gemini e ao NotebookLM para assinantes Pro e Ultra. O status de preview significa que o Google ainda está refinando o modelo antes da disponibilidade geral, o que é prática comum em implantações de IA de alto risco.
O Gemini 3.1 Pro não é sobre vencer uma corrida de benchmarks. É sobre a busca por um modelo que consiga ir além da previsão de tokens e começar a resolver problemas de forma estruturada. A direção é a correta, mas a prova de fogo será a sua adoção em produção, onde cada ciclo de CPU e cada token gerado têm um impacto direto no resultado financeiro. Quem toma decisões de tecnologia sabe que a diferença entre um modelo promissor e um modelo útil se mede em operação, não em laboratório.
Sem spam, sem compartilhamento com terceiros. Apenas você e eu.



